語言是人類智慧的結晶,文明的起源,它奧妙而多變,同樣一句話,因為文化、區域使用情境的不同,能變化出各種涵義,語言更是人與其他生物的分野,是人類獨有的特徵,要讓AI更像人,得讓它聽得懂人話,這代表AI不僅要能辨識語音,還要理解語意。
中央研究院資訊科學研究所馬偉雲副研究員說,「我們怎麼讓電腦知道,每個詞彙的意思呢?我們就必須有一個,像是一個辭典,是電腦看得懂的辭典,我們過去就是開發了一套,這樣子的知識庫,叫做「廣義知網」。」

這是AI專屬的中文大辭典,內容涵蓋九萬多個詞彙,它們都經過大量人力標注,定義出詞性、語法、結構等規則,才能提供機器進行學習,中文不像英文,每個字詞之間都有空格,為了方便機器閱讀,科學家還得先做斷詞。
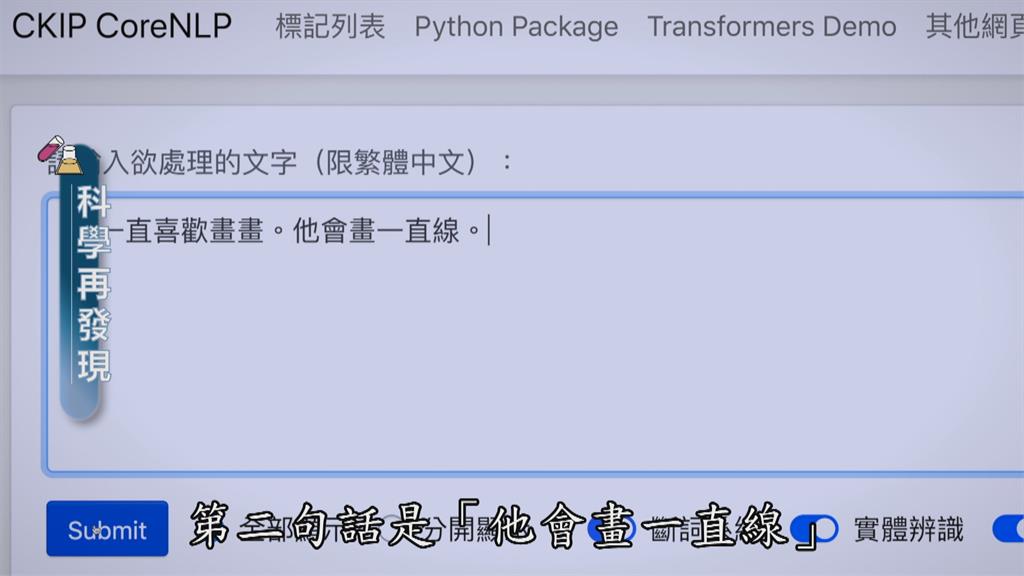
中央研究院資訊科學研究所馬偉雲副研究員說,「這邊有兩句話,第一句話是「他一直喜歡畫畫」,第二句話是「他會畫一直線」,你可以看到,這兩邊都有「一直」這個詞彙,可是它們斷出來的結果會不一樣,譬如說第一句,「一直」是一個詞,它是一個副詞,第二句話,「一直」它就不能夠合成一個詞,「直」必須和「線」合起來,變成一個詞變成「直線」,我們就會請語言學家,針對成千上萬的文章,每篇文章把它的詞彙,一個個標注出來,因為中文它的詞彙和詞彙之間,是沒有空白的,所以我們就等於去加這些空白。」
歷經十多年,中研院詞庫小組,在2019年正式開源釋出,中文斷詞系統「CkipTagger」,準確度高達97%。
中央研究院資訊科學研究所馬偉雲副研究員說,「很多電視新聞台,他們在做他們的後面的編輯,假設他們要做一些詞彙上的統計,他們就會用我們這個工具,假設你是要做一個查詢系統,你可能也需要把詞彙斷好之後,當使用者問你,他想要搜尋一個什麼樣的內容,你就可以按照,你所分析的這些詞彙來回給他,其實它的應用是非常廣泛的。」

「廣義知網」與斷詞系統,為中文的自然語言處理,打造穩固的基礎。
(民視新聞/綜合報導)
更多新聞: 確診者曾搭278次太魯閣號到花蓮 途中還換座位 縣府:屬境外移入